How to Know When to Hire DevOps Consultants
Define DevOps consulting scope by outcomes, ownership, and handoff readiness.
June 8, 2026
DevOps Engineering

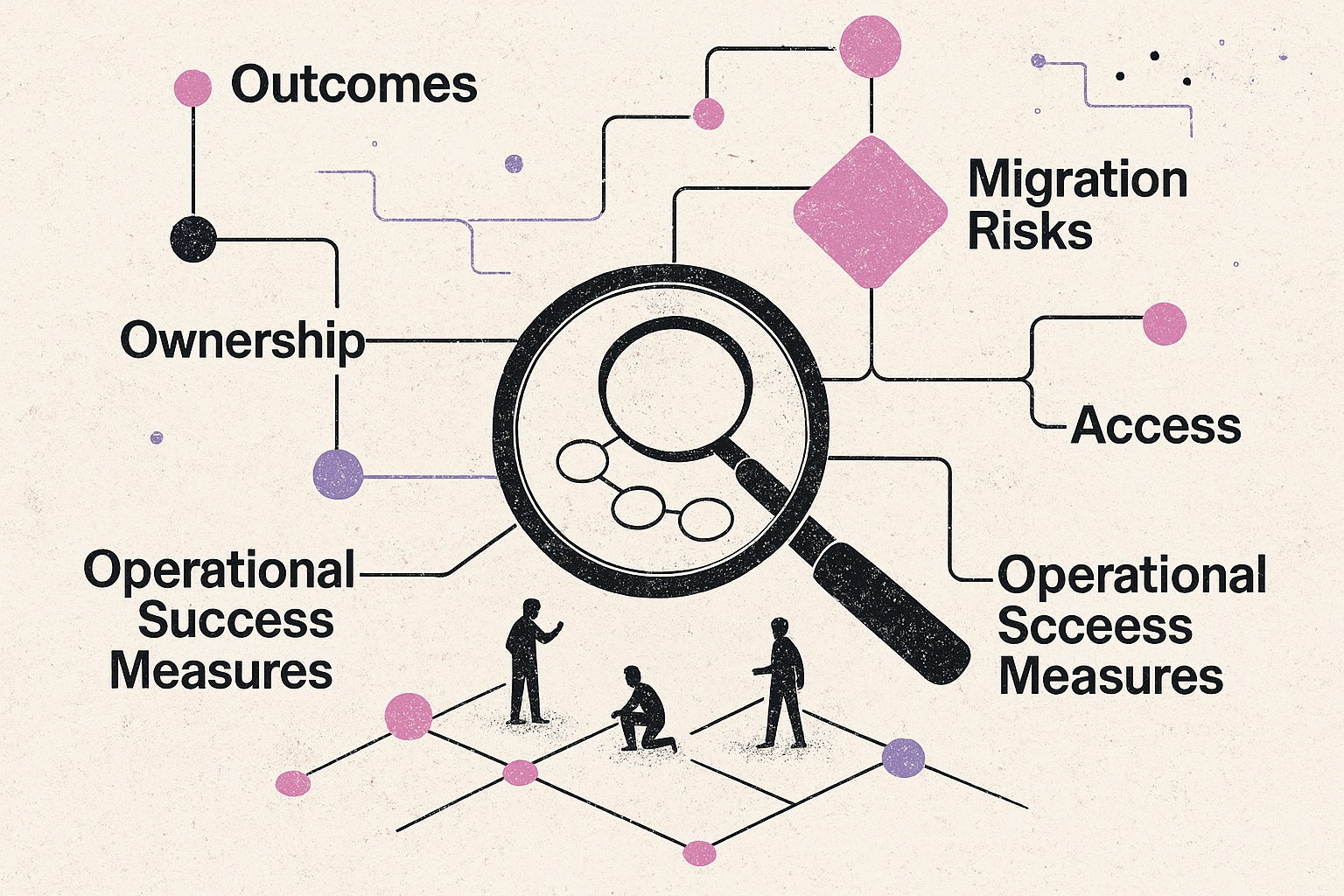
Define DevOps outcomes, ownership, access, migration risks, and operational success measures.

Teams usually ask for DevOps help when delivery slows down, deployments feel risky, cloud bills keep climbing, or production support depends on a few people who know where everything is hidden. The pressure is familiar: leadership wants faster releases, engineers want fewer interruptions, and operators want systems they can trust.
A good DevOps or platform engineering engagement should turn that pressure into a practical operating plan. It should improve how your team builds, ships, observes, and operates software. That only happens when the work is scoped around outcomes, ownership, access, risk, and measurable operational improvement.
“We need DevOps help” is too broad to scope well. It can mean cloud architecture, continuous integration and continuous delivery, infrastructure as code, Kubernetes operations, incident response, security hardening, cost reduction, migration planning, or all of the above.
Before you talk to a consultant, write down the pain in plain operational terms. Good examples include:
This framing makes the engagement concrete. It also prevents the consultant from solving the wrong problem with a familiar tool. A startup with two services and five engineers may need cleaner deployment automation and better monitoring before it needs Kubernetes. A Series B team running dozens of services may need platform standards, environment strategy, and clearer service ownership before it needs another dashboard.
Deliverables matter, but they are not enough. A Terraform repository, a new cluster, or a CI/CD pipeline can still leave the team with unclear ownership and fragile operations.
Scope the work around outcomes first, then map those outcomes to deliverables. For example:
This approach changes the conversation. Instead of asking, “Can you set up Kubernetes?” you ask, “What is the simplest platform that lets us deploy safely, scale the next set of workloads, and operate it with the team we actually have?”
That distinction matters. Kubernetes can be the right answer when you need portable orchestration, strong workload isolation, advanced scheduling, or a shared platform for many services. It can also add operational load before the team is ready. Managed container services, platform as a service, or simpler virtual machine patterns may fit better for an early product team that needs reliable shipping more than platform flexibility.
A consultant cannot give you a useful plan if the current state is vague. You do not need perfect documentation, but you do need enough context to avoid guesswork.
Prepare a short technical inventory before scoping starts:
Use real examples. “Deploys are scary” is less useful than “the last database migration required manual SQL in production, and rollback was unclear.” “Monitoring is bad” is less useful than “we get CPU alerts at night, but they rarely map to customer impact.”
You should also name constraints. If your team can only spend two hours per week reviewing infrastructure changes, the scope should reflect that. If a funding milestone requires migration in a fixed window, the plan should separate must-have risk reduction from nice-to-have cleanup.
Unclear access slows work and creates risk. Giving a consultant broad production access without boundaries creates a different risk. Scope should define how the consultant will work inside your systems before implementation begins.
At minimum, agree on:
This is especially important when the team has no dedicated site reliability engineering (SRE) or platform role. If the founding engineer remains the infrastructure owner, the consultant should design for that reality. A complex setup that only the consultant can operate is a failed engagement, even if the architecture looks clean on paper.
Good consultants will ask who will maintain the work after they leave. They should adjust tool choices, documentation, and rollout pace based on your staffing model. If they cannot explain the operational cost of their recommendations, slow down.
Many DevOps engagements involve changing live systems: moving from Heroku or Render to a cloud provider, introducing Terraform, replacing deployment pipelines, moving databases, adding Kubernetes, or restructuring cloud accounts.
These changes can improve reliability, but they can also break customer-facing systems if the migration plan is thin. Scope should include migration risk as first-class work, not as an afterthought.
For risky changes, require a plan that covers:
Do not accept “we’ll figure it out during the migration” for production systems. Discovery often reveals hidden dependencies: a cron job running on one old instance, a manually configured environment variable, a firewall rule no one remembers, or a queue consumer tied to a deployment script. The scope should leave room to find and handle that reality.
At the end of the engagement, you should be able to see a change in how the team operates. The goal is not a folder full of diagrams or a tool migration that nobody understands.
Useful success measures include:
Some of these are qualitative, but they are still measurable through team behavior. Can a new backend engineer deploy without private instructions? Can the on-call engineer find the failing dependency in minutes instead of guessing? Can leadership see which services drive cloud cost? Can the team rebuild an environment without clicking through the console?
Those answers matter more than the number of tickets closed.
Use this checklist before you sign off on a DevOps consulting engagement:
The best scope is specific enough to guide the work and flexible enough to adapt after discovery. Start with the pain your team feels in production, define the operating improvements you need, and choose tools only after that. A good engagement should leave your team with safer systems, clearer responsibilities, and less dependence on tribal knowledge.